Citoyenneté numérique : programme de formation


Principes

Nous entendons par "citoyenneté numérique" la capacité à utiliser ou produire efficacement des biens ou services numériques, que ce soit dans le cadre d'une activité politique, commerciale ou sociale.
La notion de citoyenneté numérique est fondamentale, alors que l'informatique (i) devient un élément constitutif d'un nombre croissant de biens & services de consommation, comme de production ; (ii) rend possible la réalisation d'une intelligence collective, par la mise en réseau des individus.
Malheureusement, la citoyenneté numérique est quasiment inexistante car son antithèse, l'analphabétisme informatique, est la norme plutôt que l'exception, touchant même de nombreux étudiants, et la plupart des cadres supérieurs ! La présente publication a pour ambition de rendre l'informatique compréhensible par "Mme/Mr Toulemonde", et cela dans un but d'empouvoirement.
Nous définissons la « culture informatique » en termes de théorie, pratique et apprentissage :
- théorie : la compréhension des principes élémentaires de l'informatique :
- au niveau client : principes du système d'exploitation d'un ordinateur ;
- au niveau serveur : principes des réseaux informatiques.
- pratique : la pratique de l'informatique :
- dans le cadre de la production ou de la consommation de biens ou de services, marchands ou non marchands ;
- en appliquant les principes élémentaires de la sécurité numérique.
- apprentissage : la capacité à apprendre par soi-même, aux niveaux théorique et pratique. Pour ce faire, il s'agit essentiellement de :
se libérer de la croyance dans sa propre incapacité à apprendre les principes de base de l'informatique ;
- apprendre, par la pratique, à dialoguer avec une IA ;
inscrire la démarche d'apprentissage dans la permanence, en la considérant aussi nécessaire que la pratique régulière d'une activité sportive en plein air.
La citoyenneté numérique est donc hautement utile, voire indispensable :
pour comprendre les business modèles qui déterminent nos relations avec les fournisseurs de services Internet, et réduire l'asymétrie d'information avec ces professionnels ;
pour booster notre productivité en exploitant au mieux les technologies Internet dans nos activités personnelles, marchandes et non marchandes ;
pour la démocratie directe, car elle permet de connecter les intelligences individuelles et collective.
Pour vaincre l'analphabétisme informatique, la première étape consiste à réaliser que la citoyenneté numérique passe par la maîtrise individuelle de son ordinateur (le côté "client") et de son propre site web (qui illustre la notion de "serveur").
Le présent document propose ainsi un programme d'auto-formation pratique à la citoyenneté numérique, en commençant par les principes technologiques de base de l'informatique :
- "réseau", correspond à la notion de "marché" dans le monde virtuel, mettant en relation offre et demande ;
- "client", correspond plutôt à la consommation de services informationnels ;
- "serveur", correspond plutôt à la production de ces services (traitement des données).
Le lecteur constatera que nous concevons ici la citoyenneté de façon très différente des prospectus propagés par l'appareil d'État (gouvernement, presse, autorités scientifiques, ONG, ...) en la matière, où le citoyen est vu essentiellement en tant que consommateur, et n'est considéré comme producteur que de "fake news" et de "haine". Il s'agit du discours réducteur et dénigrant d'une classe dirigeante : on est là en plein dans la propagande (négative), et pas vraiment dans une approche bienveillante visant à l'émancipation des populations.
Réseau
2.2. Modèle OSI
2.3. Routeur
Centralisé vs décentralisé
On distingue deux types de réseau (illustrés dans l'animation ci-dessous) :
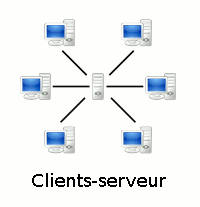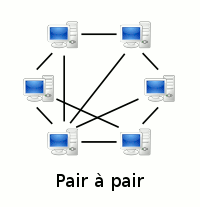
client-serveur c-à-d centralisé : des ordinateurs "serveurs" (automatiques, donc sans clavier) fournissent des services (applications et données) à votre ordinateur "client" (encore appelé "terminal", car il ne dispose que d'une seule connexion au réseau) ;
pair-à-pair c-à-d décentralisé : chaque ordinateur du réseau est à la fois client et serveur (et est alors appelé "noeud"), de sorte qu'il peut communiquer avec n'importe quel autre noeud du réseau, via un tunnel virtuel par lequel les données privées voyagent de façon cryptée, via d'autres noeuds. Sur un tel réseau, les applications peuvent y être multipliées sur un grand nombre de noeuds.
Historiquement la plupart des réseaux sont centralisés, pour des raisons technologiques et économiques, et peut-être aussi politiques. L'évolution vers l'idéal de réseau décentralisé correspond à l'évolution vers l'idéal de démocratie directe. Pour approfondir sur cette évolution voir democratiedirecte.net/reseau-decentralise.
Modèle OSI
Quel que soit le type de réseau, les fonctions clientes et serveurs ont une composante matérielle et une composante logicielle. Cela est théorisé par le modèle OSI, dont voici une version très simplifiée (le modèle OSI comporte sept couches, et non deux comme dans le schéma ci-dessous). Il modélise la communication entre deux ordinateurs comme étant l'échange de données (sous formes de bits). Celles-ci sont contenues dans des "paquets" numériques (cercle rouge), avec des instructions de transfert, appelées protocoles. Chaque protocole correspond à un même niveau de ce modèle en couches : ainsi il existe un protocole pour la couche logicielle et un autre pour la couche matérielle, chaque couche communiquant avec la couche inférieure/supérieure.
Modèle ultra simplifié (deux couches)
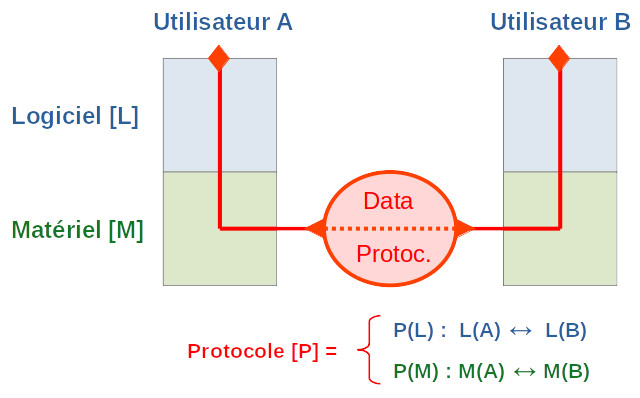
Principes élémentaires du modèle OSI : la couche "logiciels" de notre modèle en deux couches correspond aux couches 5 à 7 du modèle OSI, tandis que la couche "matériel" correspond aux couches 1 à 3. La couche 4 du modèle OSI fait donc la connexion entre les couches supérieure (logiciels) et inférieures (matériel).
Protocoles (horiz.) vs interfaces (vertic.) Dans un modèle en couche les protocoles définissent les règles du dialogue entre couches de même niveau sur des systèmes différents, cependant que les interfaces spécifient les services qu'un couche inférieur fournit à la couche qui lui est immédiatement supérieure au sein du même système [source].
Dans la dynamique chronologique verticale du modèle OSI, le protocole de chaque couche est encapsulé dans celui de la suivante. Quel que soit le sens de la communication (gauche ⇔ droite dans le schéma ci-dessus), cela va toujours d'un expéditeur/émetteur (encryptage ⇒ encapsulation) vers un destinataire/récepteur (désencapsulation ⇒ décryptage).
Encapsulation (modèle à quatre couches)

Lecture (de haut en bas) : le fichier "Données" de la couche "Application" est encapsulé dans (le datagramme de) la couche "Transport", avec l'entête (TCP) spécifique à celle-ci ⇒ le tout est encapsulé dans (le paquet de) la couche "Internet", avec l'entête (IP) spécifique à celle-ci ⇒ le tout est encapsulé dans le paquet de la couche "Liaison", avec l'entêter de trame spécifique à celle-ci.
Routeur
Les routeurs sont des serveurs très spécifiques, en l'occurrence ce sont des postes relais, fournissant un service de routage des données, pour les acheminer de l'expéditeur au destinataire. Pour ce faire, cet ordinateur spécialisé possède au moins deux cartes réseau, l'une pour les données entrantes et l'autre pour les données sortantes.

Routeur et switch assument la même fonction de connexion : entre deux réseaux pour le premier, entre machines (clientes ou serveurs) au sein d'un même réseau.
Un routeur est un ordinateur serveur, qui fournit un service de routage. Un serveur est un ordinateur qui fonctionne automatiquement, tandis qu'un client (ou terminal) est actionné par un utilisateur humain.
Le vocabulaire utilisé est parfois déroutant pour l'utilisateur non informaticien qui souhaite installer un réseau local dans l'habitation familiale. Le schéma infra, qui présente trois étapes de l'évolution d'un réseau local (ou LAN pour "local area network"), permet de comprendre sans ambiguïté la différence entre "modem", "routeur" et "gateway" :
- le modem connecte le LAN à Internet, via le fournisseur d'accès à Internet ou FAI ;
FAI / ISP. La dénomination anglophone, "Internet service provider" (ISP) est plus pertinente, car la gamme des services Internet ne se limite pas au seul accès vers le réseau, mais peut comprendre également des services applicatifs et de stockage
- le routeur gère ici la communication entre les terminaux du LAN ; plus généralement, un routeur – opérant au niveau des couches 2 (réseau local, éventuellement constitué du seul routeur) et 3 du #modele-OSI – relie des réseaux entre eux : ici le réseau local au réseau Internet ;
- le gateway combine les fonctions de modem et de routeur.
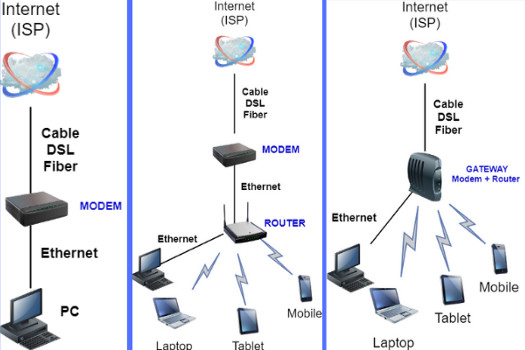
Anglais : ISP : "Internet Service Provider".
Français : FAI : Fournisseur d'Accès à Internet.
Une lecture verticale du troisième stade, permet de distinguer clairement clients et serveurs :
- le FAI fournit un service d'accès à Internet, via son serveur ;
- le gateway est le serveur du LAN ;
- les terminaux des différents utilisateurs sont des clients.
Adressage
Le routage peut opérer car chaque ordinateur (client ou serveur) est identifié par une adresse IP. À chaque adresse IP peut être attribué un nom de domaine (plus explicite et facile à retenir pour les humains). C'est notamment le cas des serveurs email et des serveur d'hébergement web.
Pourquoi une adresse IP dynamique est préférable pour un particulier : /adresse-IP-dynamique.
Pourquoi il est important d'avoir (aussi) un nom de domaine propre (pour votre adresse email et votre éventuel site web), plutôt que celui d'un fournisseur de service Internet : cf. infra #serveur.
Client
3.2. Système d'exploitation
3.3. Mémoires
3.4. Processeur
Composants d'un ordinateur
Un ordinateur est composé de matériel ("hardware") et de logiciels ("software") :
Matériel. L'ordinateur est également appelé "terminal" dans un réseau centralisé ("client-serveur"), et "noeud" dans un réseau décentralisé ("pair-à-pair"). Rappelons que le réseau Internet et les réseaux d'entreprises sont essentiellement des réseaux client-serveur (autrement dit, le réseau pair-à-pair est un idéal, notamment celui de la démocratie directe ).
Logiciel. Dans le contexte client-serveur, le terme "logiciel client" désigne un logiciel installé sur le terminal de l'utilisateur, et qui utilise un service fourni par sa version "serveur", installée sur une machine serveur distante (serveur web, serveur mail, ...).
Le schéma suivant représente les relations entre les composants élémentaires, logiciels et matériels, d'un ordinateur. L'utilisateur, via l'interface graphique d'un application, échange avec l'ordinateur des données et des instructions, sous la forme de texte alphanumérique (flèches bleues). Le traitement de ces données/instructions est opéré par du logiciel (cadres bleus) opérant lui-même dans du matériel (cadres verts). Ce dernier étant composé de systèmes électroniques, il ne peut traiter et stocker que des données binaires (flèches vertes), en l'occurrence des 1 (présence de courant) et des 0 (absence de courant).
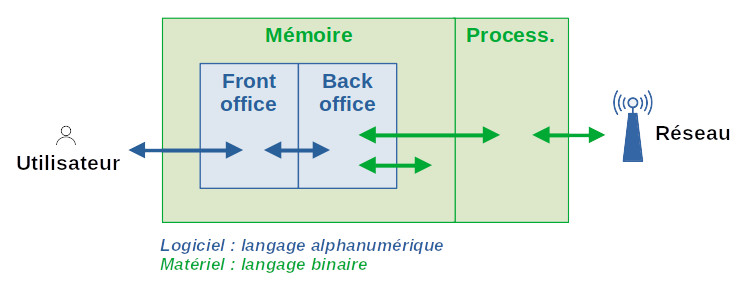
SE : système d'exploitation.
Exercice : interpréter la flèche de connexion dans le cadre du modèle du #modele-OSI exposé supra.
Dans les sections suivantes, nous allons développer les notions de système d'exploitation (logiciels), mémoire et processeur (matériels).
Système d'exploitation
Le système d'exploitation (SE) est l'ensemble des programmes dont un ordinateur a besoin pour fonctionner (démarrage, gestion de la mémoire, des matériels périphériques, etc.). Il est un interface entre les applications et le matériel (processeur et mémoire). Et pour l'utilisateur avancé, il peut être un interface pour la configuration du matériel et les applications (flèche bleue en bas à gauche dans le schéma précédant).
L'utilisateur avancé d'un ordinateur peut communiquer directement avec le SE via une interface graphique minimaliste (appelée console ou terminal de l'ordinateur) dans lequel l'utilisateur interagit avec le SE au moyen de lignes de commandes (commandes Unix pour les SE Linux). Ces commandes, qui peuvent être combinées, démultiplient la productivité (effectuer des opérations sur plusieurs fichiers en même temps, automatiser des tâches récurrentes, etc.). Approfondir : ./utiliser#ligne-commandes.
Suites logicielles libres vs propriétaires
Lorsqu'on parle de "système d'exploitation", du point de vue des utilisateurs, on entend en réalité "suite logicielle" c-à-d le SE plus les applications classiques qu'il permet de faire fonctionner : navigateur, lecteur vidéo, traitement de texte, tableur, etc.
Les SE les plus répandus sur les machines clients sont MS Windows et MacOS. Par contre sur les serveurs (notamment les serveurs web, les serveurs de base de données, et les serveurs de virtualisation), le SE qui domine (très largement) est Linux, grâce à sa flexibilité, sa sécurité, sa performance et le fait qu'il est open source.
Classement des SE Linux les plus utilisés sur les serveurs [source] :
- Ubuntu Server
- CentOS
- Debian
- Red Hat Enterprise Linux (RHEL)
- SUSE Linux Enterprise Server (SLES)
La première place d'Ubuntu server est le fruit de son support commercial par Canonical.
Pourquoi les particuliers n'utilisent-ils pas Linux plutôt que MS Windows et MacOS, alors que Linux est plus efficace, gratuit et open source ? Quelques éléments de réponse : la publicité, le manque de support des gouvernements pour le logiciel libre, la corruption de décideurs industriels et politiques, ...
Pourquoi nous utilisons Debian : /meilleur-choix :
Surprenante
disparité...
Alors que Linux (logiciel libre) est le système d'exploitation (SE) de la totalité des 500 super-ordinateurs les plus puissants du monde [source p. 444], et de plus de 75% des serveurs web dans le monde [source], comment se fait-il que ce dernier pourcentage tombe à moins de 5% pour ce qui concerne le côté client c-à-d les ordinateurs et smartphones de Mme./M. Toulemonde [source] ?
Android, le SE de la plupart des smartphones (80%), et de 40% de l'ensemble des terminaux web, est certes fondé sur le noyau Linux. Mais il s'agit là uniquement du noyau. Or dans le présent document, lorsque nous parlons de SE, c'est au sens de Linux Debian, c-à-d y compris les applications (évidemment libres) qui tournent sur ce noyau (tableur, traitement d'image, etc). Sur les smartphones la plupart des applications ne sont pas des logiciels libres. Rappelons enfin une différence fondamentale entre portable et smartphone : seul le portable est utilisable comme moyen de production, alors que le smartphone est essentiellement un moyen de consommation ...
Le système d'exploitation est constitué de programmes (sous formes de fichiers) et de fichiers de configuration (appelés pilotes ou "drivers" en anglais). Tous ces fichiers sont installés dans la mémoire de stockage de l'ordinateur.
Mémoires
Une "mémoire" est un matériel pouvant stocker des données informatiques (des bits inscrits sur différents supports). Il est important de comprendre les spécificités des divers types de mémoire :
- la mémoire de stockage est en écriture et lecture : c'est le disque dur de l'ordinateur ou encore les clés USB;
- les mémoires de travail :
RAM (dite "vive" ou "volatile") : mémoire en lecture et écriture ; son contenu disparaît à la fermeture de l'ordinateur ; accès est très rapide (car direct) ; la ou les barrette de RAM peuvent être remplacées en ouvrant le boîtier de l'ordinateur ; c'est la mémoire du modèle d'ordinateur de von Neumann ;
La mémoire virtuelle (aussi apppelée "fichier d'échange") est une technique de gestion de la mémoire utilisée par le système d'exploitation, qui simule de la RAM supplémentaire en utilisant de l'espace sur le disque. Elle est cependant beaucoup plus lente que la RAM, car le disque dur est bien moins performant pour accéder aux données.
ROM (dite "morte" ou "non volatile") : mémoire en lecture seule ; son contenu persiste à la fermeture de l'ordinateur ; traditionnellement utilisée pour stocker le firmware, et notamment le BIOS/UEFI (programmes de démarrage de l'ordinateur), et souvent intégrée sur la carte mère.
Une capacité de mémoire de travail RAM insuffisante peut ralentir le fonctionnement de l'ordinateur. Le terme "insuffisant" est relatif au profil d'utilisation de l'ordinateur. Par exemple il est recommandé d'éviter l'ouverture simultanée de nombreuses instances d'une même application (notamment les applications graphiques).

Processeur
Le processeur, encore appelé "unité centrale" est le composant électronique qui exécute les instructions des programmes et effectue les calculs nécessaires. Sa taille est d'environ 1 cm2, et son poids de quelques grammes.
Le processeur est donc le composant essentiel de l'ordinateur. Les autres composants servent à stocker des données, afficher des informations, gérer l'énergie, connecter d'autres appareils, etc.
Le processeur peut contenir également du code (autre nom pour "programme"), que l'on peut considérer comme "gravé" dans celui-ci, dans la mesure où il n'est pas possible de le modifier autrement qu'en remplaçant le processeur en question, contrairement aux fichiers installable en mémoire de stockage, qui sont lisibles et éditables (par l'utilisateur autorisé, dit "administrateur" du système d'exploitation de l'ordinateur). C'est malheureusement une tendance croissante qui limite le contrôle de l'utilisateur sur son outil de travail.
Menaces sur l'informatique libre
Les fabricants de matériels informatiques tentent d'accaparer du pouvoir commercial en déplaçant de plus en plus de contrôle vers du logiciel gravé dans la carte-mère, c-à-d en déplaçant les fonctions du SE de la partie "Mémoire" vers la partie "Processeur" dans le schéma ci-dessus. Ce faisant, les fabricant réduisent dangereusement le contrôle que peut exercer l'utilisateur sur son ordinateur via le SE. Ils se justifient en arguant que cela augmenterait la sécurité de l'ordinateur ...
- approfondir : /informatique-libre#logiciel-materiel-donnees
- réagir : /informatique-libre#action-citoyenne
https://linux-debian.net/citoyennete-numerique#menace-informatique-libre
Pour approfondir sur la notion d'ordinateur :
- democratiedirecte.net/intelligence#IA-architecture
- democratiedirecte.net/intelligence#IA-materiel
- democratiedirecte.net/intelligence#programme
- democratiedirecte.net/intelligence#systeme-exploitation
Serveur
4.2. e-Mail
4.3. Site web
Principes
Le serveur est la machine centrale d'un réseau centralisé.
À contrario, dans un réseau décentralisé, toutes les machines clientes (ont dit alors "noeuds" plutôt que "terminaux") sont à la fois cliente ... et serveur.
Un "serveur" est un ordinateur (généralement sans clavier car fonctionnant automatiquement) sur lequel est installé un logiciel serveur fournissant un service spécifique aux logiciels clients correspondant à chacun de ces services, et installés sur les ordinateurs d'utilisateurs distants (les clients, cette fois commerciaux, des fournisseurs de services Internet, ou FSI).
Les serveurs sont souvent combinés. Deux serveurs de base de quasiment tous les autres sont :
- le serveur web, pour l'hébergement de sites web ;
- le serveur mail, pour l'échange de messages.
L'ouverture d'Internet au grand public, au début des années 1990, fut réalisée essentiellement par les opérateurs de téléphonie, qui proposaient l'accès à Internet, plus les services de base que sont l'email et l'hébergement de sites web.
Depuis il y a eu une spécialisation (ou un retour au "core business") :
- d'une part les fournisseurs d'accès à Internet, dont l'activité correspond plutôt à la couche matérielle (télécom) du modèle OSI (cf. schéma ci-dessous) ;
- d'autre part les fournisseurs de services Internet (email, hébergement, réseaux sociaux, ...), dont l'activité correspond plutôt à la couche logicielle (applications) du modèle OSI.
Principes élémentaires du modèle OSI : la couche "logiciels" de notre modèle en deux couches correspond aux couches 5 à 7 du modèle OSI, tandis que la couche "matériel" correspond aux couches 1 à 3. La couche 4 du modèle OSI fait donc la connexion entre les couches supérieure (logiciels) et inférieures (matériel).
L'analphabétisme informatique étant largement répandu, la plupart des utilisateurs particuliers se limitent à une posture passive de consommateurs de services Internet :
leur adresse email n'est pas en nom de domaine propre, c-à-d qu'elle est de type nom@fsi.com au lieu de (par exemple) prenom@nom.net, ce qui permet au FSI d'utiliser le contenu des emails à des fins commerciales, de placer des publicités dans les emails et dans l'interface de gestion, etc ;
ils surfent sur Internet (notamment les réseaux sociaux), mais la plupart n'ont pas de site web personnel (et la plupart de ceux qui en ont un, ce n'est pas en nom de domaine propre, c-à-d que leur adresse web est de type nom.fsi.com plutôt que par exemple nom.net, ce qui donne le droit au FSI d'utiliser le contenu du site web à des fins commerciales, de placer des publicités sur celui-ci, ainsi que sur son interface de gestion, etc).
Dans cette section, nous allons montrer comment procéder, aux personnes désireuses d'assumer leur citoyenneté numérique, c-à-d qui veulent se protéger du consumérisme numérique, et étendre leur maîtrise des principes de base des technologies Internet, dans un but de production de biens ou services, à caractère privé (activités sociales ou politiques) ou professionnel (artisans indépendants).
Pour ce faire, voici trois principes de base à appliquer :
- au niveau serveur :
maximiser votre contrôle personnel des services internet de base, à savoir email et site web, car ils sont à la base de tous les autres ;
commencer par louer un nom de domaine propre, car c'est ce qui vous permettra notamment de ne pas dépendre d'un FSI, et de pouvoir facilement passer à un concurrent si nécessaire (ce qui arrive toujours un jour où l'autre...).
- au niveau client : libérer votre ordinateur, c-à-d remplacer le système d'exploitation propriétaire (MS Windows, macOS,...) par un SE libre. Je recommande /linux-debian), dont la particularité est qu'il est conçu pour fonctionner aussi bien comme client que comme serveur. Ainsi vous participez à l'évolution d'Internet vers un réseau décentralisé !
Location de noms de domaine
Liste de fournisseurs de nom de domaine répondant aux conditions suivantes :
- proposent la location de noms de domaines, sans que cette location soit liée à la location d'autres services (email, hébergement, ...) ;
- proposent une interface francophone.
Liste non exhaustive, classée par ordre alphabétique :
https://linux-debian.net/citoyennete-numerique.php#location-nom-domaine
Pour minimiser votre dépendance par rapport aux FSI, ayez une adresse email en nom de domaine propre (exemple : jortay.net).
Vous louez donc un nom de domaine, que vous pourrez utiliser également pour votre site web également en nom de domaine propre.
Avoir un email en nom de domaine propre ne vous empêche pas d'avoir d'autres adresses email, cette fois sous le nom de domaine d'un FSI (exemple : gmail.com).
Configuration client mail. Comment configurer correctement votre client e-mail, pour un contrôle maximal de vos échanges email : /installer#email ;
Site web
4.3.2. Site clé sur porte
4.3.3. Site statique
4.3.4. Site dynamique
Garder le contrôle
Évitez comme la peste les services de page web personnelle prétendument "gratuits", qui affichent des publicités, ou dont les conditions d’utilisation stipulent (généralement dans un jargon juridique difficilement compréhensible par les non-juristes) que l'utilisateur cède la propriété de ses données personnelles, y compris les droits d'auteur de ses éventuelles créations publiées sur la page web mise à sa disposition.
Pour éviter cette situation, il vous faut avoir le contrôle de l'hébergement du site web.
Pour bien comprendre la problématique, commençons par rappeler la différence entre ces trois notions :
- nom de domaine : une adresse ;
- hébergement du site web : une machine serveur ;
- le site web : le logiciel serveur.
Location hébergement. La plupart des fournisseurs de services Internet (FSI) mentionnés supra dans #location-nom-domaine proposent également un service d'hébergement. Vous n'êtes pas obligé d'utiliser les services d'un même FSI pour l'hébergement de votre site web et la location du nom de domaine. Cette stratégie facilite votre éventuel changement d'hébergeur si sa qualité de services se dégrade, ou si un concurrent propose une offre avec un meilleur rapport qualité/prix.
Business modèle
Un utilisateur particulier hébergera son site web sur le serveur web d'un ISP, tandis qu'une entreprise hébergera elle-même son site web avec son propre routeur (c-à-d physiquement hébergé dans ses propres bâtiments). Alternativement, l'entreprise peut, à l'instar du particulier, confier à un ISP l'hébergement de son serveur Internet : site web ("front office") et base de données ("back office"). Ainsi l'entreprise "externalise" (sous-traite) la gestion des aspects techniques les plus complexes de l'hébergement, mais avec l'inconvénient que l'ISP a accès à toutes les données passant par le serveur externalisé (NB : c'est aussi le cas des opérateurs du réseau télécom).
Force est cependant de constater que, via le service de "cloud", de nombreuses entreprises ont choisi la sous-traitance, confiant ainsi leurs données (dont celles de leurs clients et fournisseurs !) à l'ISP, ainsi qu'aux propres sous-traitants de l'ISP (avec lesquels ces entreprises n'ont aucune relation contractuelle ...). Cela pose de sérieux problèmes de confidentialité ... dont la plupart des dirigeants d'entreprise (et leur clients/fournisseurs) n'ont qu'une perception très naïve, voire sont complètement ignorants. Idéalement, dans ce business modèle de sous-traitance, les données et les programmes devraient être protégés (c’est-à-dire chiffrés) y compris pendant les traitements, ce qui impose des modifications tant du matériel que des logiciels [source]. Mais les sous-traitants sont généralement dans l'incapacité de vérifier la qualité de ce service.
Site "clé sur porte"
La plupart des offres d'hébergement comprennent une option de site "clé sur porte" (par exemple WordPress), comprise dans l'offre d'hébergement et installable en quelques clics. Cette solution vous permet de faire vous-même les mises à jour de votre contenu (via une interface de gestion).
Évitez donc également l'arnaque des "développeurs web" qui prétendent "développer" votre site web alors qu'ils ne font rien d'autre qu'installer un site clé sur porte (donc en quelques clics, via le même interface de gestion !), et puis vous facturent chaque mise à jour ...
J'ai testé la formule clé sur porte (après avoir commencé par développer moi-même mon site web) ... et constaté qu'elle est beaucoup moins satisfaisante pour qui a la volonté de développer lui-même son site web (ce qui ne requiert pas d'être informaticien !). L'idéal c'est clairement d'apprendre les technologies de base d'Internet, par la pratique, en créant un site web élémentaire dit "statique". Par la suite, vous pourrez développer votre maîtrise en le convertissant en site "dynamique".
Commencez "petit", mais faites-le bien ! Et surtout, commencez, puisque l'informatique est fondamentale !
Site statique
Commencez par créer une simple page d'accueil (nommée index.html), par exemple avec l'éditeur Bluefish. Ce faisant vous apprendrez les langages web de base que sont HTML et CSS (cf. infra #programmation et #methode-apprentissage).
Contenu de index.html :
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="utf-8">
</head>
<body>
Hello, ceci est mon site web.
</body>
</html>
Une fois cette page index.html conçue localement (pour la visionner, il suffit de l'ouvrir à partir de votre navigateur), vous pourrez alors la télécharger sur votre hébergement en utilisant un client FTP (par exemple FileZilla, dont une version francophone est comprise dans Linux Debian).
Site dynamique
Pour un site plus évolué, permettant de gérer facilement un grand nombre de pages (grâce à PHP) et s'adaptant aux types d'écran (grâce à Bootstrap), voici la procédure pour développer votre localement c-à-d sur votre ordinateur (il vous restera alors à le télécharger sur votre hébergement, comme pour un site statique) :
- installer sur votre ordinateur la suite LAMP (nécessaire au moins pour visionner localement un site dynamique,avant de le télécharger sur le serveur de votre hébergeur), qui est composé de :
- Apache : serveur web ;
- MySQL : base de données ;
- PHP : langage de programmation pour fonctions web dynamiques.
- vos trois fichiers de base :
index.php :
<?php include 'top.php' ; ?>
Hello, ceci est mon site web.
<?php include 'bottom.php' ; ?>top.php :
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="utf-8">
<!-- BOOTSTRAP : -->
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.1.3/dist/css/bootstrap.min.css" rel="stylesheet">
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.1.3/dist/js/bootstrap.bundle.min.js"></script>
</head>
<body>bottom.php :
</body>
</html>
NB : À ce stade vous avez acquis les bases pour la gestion de projets web.
Modules
Celles qui veulent aller encore plus loin développeront leurs propres modules applications, comme par exemple un module d'abonnement/désabonnement à une infolettre, connecté à une base de données en ligne (pour vous y aider, voici un plan de base pour le développement). Ainsi vous approfondirez votre connaissance de PHP, découvrirez JavaScript et SQL, et vous frotterez aux rudiments de la sécurisation (dont la cryptographie).
À ce stade vous avez acquis les bases pour la gestion de site web ou le développement d'applications web.
Inscrivez ces apprentissages dans la permanence de votre projet de vie et mode de vie (par petites doses, mais régulièrement).
Programmation
Maîtriser pleinement son noeud dans le réseau de l'intelligence collective requiert d'être en mesure de programmer (chacun à son niveau). Cependant, il n'existe pas de langage de programmation universel, permettant de tout faire et efficacement ⇒ il importe de connaître une combinaison de langages complémentaires ("multilinguisme numérique").
La combinaison la plus fréquente est probablement :
| Ordinateur | Bash | Automatiser et coordonner l'exécution de programmes. |
wikipedia
linuxdebian |
|---|---|---|---|
| Python | Écrire des programmes (on dit aussi algorithmes). |
wikipedia
w3schools | |
| Internet | HTML | Afficher les objets d'une page web (paragraphes, titres, images, formulaires, ...). |
wikipedia
mozilla w3schools |
| CSS | Déterminer le style (taille, couleur, etc) des objets d'une page web. |
wikipedia
mozilla w3schools |
|
| JavaScript | Écrire des programmes, exécutés par le client web (c-à-d le navigateur). Langage spécialisé dans les interactions entre l'utilisateur et la page web (mais permet aussi des interaction avec le serveur web). |
wikipedia
w3schools |
|
| PHP | Écrire des programmes, exécutés par le serveur web (NB : ⇒ le code PHP n'apparaît pas dans le code source de la page web téléchargée). Langage spécialisé dans les interactions entre l'utilisateur et le serveur web . |
wikipedia
w3schools |
Vert : basique. Rouge : avancé.
Malgré leurs spécificités, les langages informatiques reposent sur des principes élémentaires de programmation, qui sont universels (*). Par conséquent, c'est l'étude du premier langage avancé qui demande le plus d'efforts. Rappelons que c'est par la pratique, et non par l'étude théorique, que l'on acquiert une compréhension intuitive des principes élémentaires de programmation d'algorithmes. Voir à cet égard la section infra #methode-apprentissage.
(*) Exercice : pour constater la (relative) réalité de cette universalité, repérez les notions récurrentes entre différents langages avancés (JavaScript, PHP, Python, ...), dans la première partie de la colonne de gauche de w3schools.com.
Enfin, qui maîtrise les six langages du tableau ci-dessus peut quasiment tout faire en matière de programmation (notamment grâce aux extensions, telles que MySQL pour Python et PHP).
Apprentissage
Pour réaliser ce programme d'auto-apprentissage par la pratique, ne vous fixez pas de dates mais plutôt la règle "un petit peu, régulièrement" :
- régulièrement : si possible tous les jours, mais au moins une fois par semaine ;
- un petit peu : si vous travaillez chaque jour, des séances de 30 à 60 minutes suffiront (à la place de la TV du soir !).
À la fin de chaque séance, notez l'objectif à réaliser lors de la prochaine. Entre-temps, la façon de faire vous apparaîtra avec plus de clarté. Et fixez-vous des objectifs modestes, facilement réalisables, étant donné le temps imparti (idéalement, chaque séance devrait se conclure par la réalisation de son objectif). Soyez la tortue et non le lièvre de la fable !
N'apprenez pas pour le seul plaisir d'apprendre, mais aussi et surtout pour réaliser des objectifs concrets : enregistrer un nom de domaine, louer un espace web, réaliser une page d'accueil basique pour le site web, la télécharger sur votre espace d'hébergement, ....
Vous l'avez compris : le développement de vos compétences en informatique doit devenir un hobby, aussi indispensable que la pratique régulière d'une activité sportive ou artistique.
Enfin, commencez dès maintenant : ne reportez pas le début, car c'est la meilleure façon de ne jamais commencer !
Lorsque vous aurez achevé l'auto-formation de base que nous vous avons proposée dans les deux sections précédentes ("Client" et "Serveur"), vous serez en mesure d'entamer notre programme d'auto-formation au nec plus ultra de la citoyenneté : participer à la création d'un réseau mobile décentralisé : reseau-wifi-decentralise.
Ressources
Voici d'autres liens pour t'aider à réaliser ce programme de formation par la pratique :
-
Formations gratuites :
- Système d'exploitation Linux :
- Site web : openclassrooms.com/apprenez-a-creer-votre-site-web-avec-html5-et-css3
- Langages de programmation du web (html, css, javascript, php, etc), en anglais mais grande qualité didactique : w3schools.com
Posez n'importe quelle question à une IA conversationnelle, qui vous donne en quelques secondes une réponse complète et précise (NB : à interpréter toujours avec un sens critique ...) : chatgpt.com ; claude.ai ; deepseek.com ; gemini.google.com ; meta.ai ; mistral.ai ; perplexity.ai ; ...
Voir aussi :
- Vue "d'hélicoptère" du développement web (eng) :
- Popularité des langages de programmation github.io
Praxis
8.2. Messagerie
8.3. Hygiene numérique
8.4. Civilité numérique
Sécurité
Voir : /utiliser#securisation
Messagerie
8.2.2. Gestion qualitative (spam)
8.2.3. Usurpation d'e-mail
Gestion quantitative
La gestion quantitative de votre messagerie (email + réseaux sociaux) vise à ne pas vous laisser submerger par une quantité ingérable de messages (dont en outre la plupart ont une valeur informationnelle quasiment nulle, voire négative, mais cela relève de la gestion qualitative, traitée infra) :
- email : ayez deux adresses email, une "publique" (ex: contact@site.net) et une "privée" (ex: prenom1@site.net) ⇒ lorsqu'il apparaît que votre adresse privée est de facto devenue publique, créez une nouvelle adresse privée en augmentant le numéro de la partie locale (à gauche de l'arobase) ⇒ vous avez maintenant deux adresses publiques (officielle : contact@site.net ; non officielle : prenom1@site.net) et une nouvelle adresse privée (prenom2@site.net) ; fixez un nombre maximum d'emails à lire quotidiennement ⇒ dans les messages publics non encore lus, effacez quotidiennement les plus anciens dépassant ce nombre.
NB : la fonction tri de votre client email vous permet de regrouper les messages par date, adresse destinataire (votre adresse privée, vos adresses publiques), ...
- réseaux sociaux : évitez de communiquer via les réseaux sociaux, car ils sont conçus pour vous rendre accros, de sorte que vous ne savez plus vous en passer ⇒ il en résulte que :
- vous pouvez êtres soumis à des mesures de contrôle social et de propagande (notamment au moyen de bots se faisant passer pour des humains), et cela même dans les réseaux sociaux supposément "indépendants" et "libres" ;
- vous êtes confronté à des publicités commerciales (dont beaucoup sont masquées sous formes de messages non publicitaires), ce qui vous incite à consommer et donc à polluer ;
- vous gaspillez énormément de temps, qui pourrait être consacré à des activités plus utiles.
Pour communiquez, préférez le couple "email, site web" à nom de domaine propre (prenom@monsite.net, www.monsite.net).
Gestion qualitative (spam)
Contrôlez-vous régulièrement le contenu de votre dossier Spams/Pourriels, qui contient les courriels indésirables ? C'est important de le faire car des emails qui ne sont pas indésirables peuvent y être classés par erreur. Sans cette vérification, vous risquez donc de ne pas voir des courriels importants qui vous ont été envoyés par des parents, amis, relations professionnelles ou sociales, ou encore l'administration publique !
Selon ChatGPT, 70 à 80 % de la population ne vérifie pas le contenu de sa boîte Spam !
Vous pouvez donc être victime de ces ratés dans deux types de cas :
en tant que destinataire : des courriels ne parviennent pas dans votre boîte de réception ;
en tant qu'expéditeur : vos destinataires ne voient pas les emails que vous leur avez envoyés, si votre adresse email a été classée par erreur comme "expéditrice de pourriels" (ou "spammeuse").
Comment fonctionne ce système, malheureusement imparfait, de filtrage des emails ? Une adresse email peut être marquée comme spammeuse de deux façons :
- Signalement manuel par les destinataires
Action utilisateur : lorsqu'un destinataire reçoit un email indésirable ou jugé suspect, il peut choisir de signaler manuellement cet email comme "spam" ou "pourriel" via son interface de gestion des emails.
Conséquence : lorsque plusieurs destinataires signalent le même expéditeur comme spammeur, les fournisseurs de services de messagerie peuvent marquer l'adresse de l'expéditeur comme suspecte et rediriger automatiquement ses futurs emails vers les dossiers spam des autres utilisateurs.
- Détection automatique par les filtres anti-spam
Filtres automatiques : les systèmes de messagerie utilisent des algorithmes et des filtres anti-spam basés sur plusieurs critères (contenu des emails, fréquence d'envoi, adresse IP de l'expéditeur, authentification des emails, présence sur des listes noires, etc.).
Conséquence : si l'adresse d'un expéditeur correspond à des critères utilisés pour détecter les spams (par exemple, envoi massif d'emails, contenu suspect ou liens malveillants), elle peut être automatiquement classée comme "expéditrice de pourriels" sans que les utilisateurs aient à signaler manuellement les emails.
Limitation : des adresses email sont régulièrement marquées comme spammeuses par erreur, car les filtres ne peuvent pas gérer parfaitement la complexité et la subjectivité des situations.
Comment gérer au mieux ces situations :
- en tant que destinataire :
Vérifiez régulièrement votre dossier Spams/Pourriels/Indésirables, puis videz-le. La fréquence de ces vérifications devrait être journalière.
Si l'adresse email d'une de vos relations est marquée par erreur comme spammeuses (c-à-d expéditrice de spams/pourriels), comment la démarquer ? Vous ne pouvez agir qu'à votre niveau (signalement manuel par les destinataires). Appliquez les deux mesures suivantes :
dans votre boîte de réception, cliquez-droit sur l'adresse de l'expéditeur ⇒ dans le menu qui apparaît alors cliquez sur Ajouter dans le carnet d'adresses ;
Sur Mac, il n'y a pas de clic-droit sur la souris ⇒ il faut appuyer sur la touche "Contrôle" en même temps que vous cliquer sur l'adresse email ⇒ vous ferez apparaître le menu dans lequel apparaît l'option "Ajouter dans le carnet d'adresses"
dans votre boîte de réception, cliquez-droit sur l'adresse de l'expéditeur ⇒ dans le menu qui apparaît alors cliquez sur Marquer comme non Pourriel.
Continuez cependant de vérifier régulièrement votre dossier Spams car aucune mesure n'est efficace à 100 %.
- en tant qu'expéditeur :
Votre adresse email est-elle marquée comme spammeuse (par erreur ou non ...) ? Vous pouvez obtenir une réponse partielle à cette question en allant vérifier la liste noire d'entreprises spécialisées dans l'identification d'adresses spammeuses : check.spamhaus.org ; barracudacentral.org/lookups ; mxtoolbox.com ; multirbl.valli.org ; ...
Si vous êtes gestionnaire d'une infolettre, n'inscrivez jamais des personnes sans leur consentement, et veillez à mentionner une fonction de désabonnement dans l'infolettre.
Usurpation d'email
L'usurpation de l'adresse email d'un tiers ("email spoofing" en anglais), pour envoyer des emails en son nom, est un phénomène aussi fréquent que méconnu de la plupart des utilisateurs d'Internet. L'usurpation des e-mails est possible car le protocole de messagerie Internet (SMTP) n'intègre pas de mécanisme d'authentification des adresses. Ainsi, une méthode pour envoyer un mail en usurpant une adresse email (c-à-d en mentionnant celle-ci à la place de la véritable adresse expéditrice) consiste à utiliser un serveur de messagerie dont le port SMTP est mal configuré (ou intentionnellement "mal" configuré...).
Des protocoles et des mécanismes d'authentification des adresses e-mail ont été développés pour pour permettre aux administrateurs de serveurs mails de neutraliser la plupart des usurpations d'e-mails, et de les classer comme spams. Malheureusement, partout dans le monde, des serveurs de messagerie SMTP n'appliquent pas (ou incorrectement) ces mesures de sécurité. Le graphique suivant schématise la problématique.
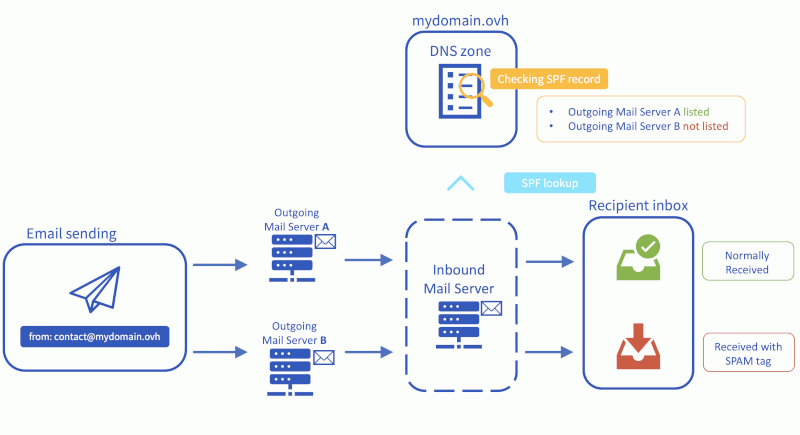 Source : ovh.com
Source : ovh.com
Comment vérifier si l'expéditeur affiché est usurpé :
- la première chose à vérifier est la présence de votre adresse dans le champs "À:" : si elle est absente, jetez ce mail à la poubelle car il s'agit très probablement d'une tentative de hameçonnage ;
- sur tout lien de l'email sur lequel vous seriez susceptible de cliquer, positionnez simplement le curseur, et lisez l'adresse réelle du lien (adresse email, page web, ...), qui apparaît généralement en bas à gauche de votre interface ⇒ si ce lien vous paraît suspect, passez à l'étape suivante ... ;
- sélectionnez l'email dans votre boîte de réception ;
- dans la barre de menu de votre gestionnaire d'email cliquez sur "Affichage" > "Source du message" (ou faites CTRL+U) ;
- sélectionnez l'ensemble de la source (CTRL+A), puis copiez-la dans un fichier txt ;
- dans ce fichier txt cherchez dkim= (CTRL+F)
- si vous trouvez dkim=pass ⇒ il n'y a probablement pas usurpation ;
- si vous trouvez dkim=fail ⇒ une usurpation peut en être la cause.
Comment identifier le serveur exploité par l'usurpateur :
- dans ce fichier txt cherchez helo= (CTRL+F).
N.B. Dans la source du mail, il peut y voir plusieurs occurrences des chaînes de caractères recherchées.
Si vous voulez envoyer une copie du mail frauduleux à la personne ou organisation dont l'adresse a été usurpée (cas fréquents : fournisseurs Internet et banques) ne copiez surtout pas l'adresse mentionnée dans l'email frauduleux, car elle peut-avoir été usurpée par modification difficilement discernable (par exemple en remplaçant un l minuscule par un I majuscule, ou un O majuscule par 0).
Pour approfondir sur l'usurpation d'email voici un bon article sur le sujet. Avec un bémol cependant : l'article étant de nature commerciale, et rédigé par une entreprise proposant des services de protection informatique aux entreprises, il en résulte que l'article n'évoque quasiment pas les usurpations d'identité dans le cadre politique (par exemple pour salir la réputation d'opposants politiques) ou privé (par exemple l'usurpation de votre identité par une relation sociale qui veut vous nuire).
Hygiène numérique
2. Consommation vs sobriété numérique
3. Production numérique
Principes
En matière informatique, comme dans beaucoup d'autres, le contenant détermine considérablement le contenu. Ainsi, les écrans de tailles extrêmes, c-à-d petits (smartphone) et grands (TV) écrans, sont essentiellement des interfaces de consommation, tandis que les écrans de taille moyenne (ordinateur portable) sont essentiellement des interfaces de production. La sobriété numérique consiste à préférer les interfaces de production, à ceux conçus spécifiquement pour la consommation. Autrement dit, il importe de faire le tri entre les technologies numériques selon que leur ratio avantages/inconvénients est favorable ou défavorable.
Consommation vs sobriété numérique
L'addiction aux écrans de consommation, c-à-d les écrans de petite taille (smartphone) et de grande taille (TV) :
- est fortement chronophage ;
- inhibe gravement la sociabilité ;
- dégrade les capacités cognitives [source] ;
conditionne les esprits, à des fins économiques (publicité) et politiques (propagande).
Cela ne veut pas dire que la TV et le smartphone n'ont pas d'avantages, mais que leur ratio avantages/inconvénients est défavorable, et que par conséquent leur utilisation est irrationnelle et nuisible.
C'est pourquoi, il est vivement recommandé :
- de remplacer le smartphone par un téléphone mobile basique ;
- de bannir la TV (vraiment, c-à-d détruire l'écran TV et supprimer l'abonnement TV).
Quelques suggestions :
je préfère m'informer (via mon ordinateur portable) auprès des sources originelles (en m'abonnant à leur infolettre), plutôt qu'en passant par l'intermédiaire d'entreprises "d'information" ou de réseaux sociaux.
je préfère également m'informer pas le médium textuel plutôt que vidéo, car ce dernier rend difficile la lecture non séquentielle, et donc l'analyse. Le langage vidéo favorise certes la perception intuitive, mais également émotionnelle, ce qui est parfait pour l'art, mais peut conduire à des dérives et abus dans les messages informationnels ou scientifiques.
pour s'opposer à l'usage forcé du code QR, il est impératif de participer à augmenter le pourcentage de la population qui ne possède pas le matériel nécessaire, c-à-d le smartphone.
Le contrôle social par les médias
Dès les années 1970, la classe dirigeante a imposé la télévision de masse par câble, lequel passe généralement par les façades des maisons, sans que le propriétaire puisse s'y opposer ! Aujourd'hui, cette même classe dirigeante inculque l'usage du smartphone. Ainsi l'Union européenne – qui a également été imposée aux populations, par des industriels européens [source] – finance des sites web de propagande, incitant les parents à ne pas protéger leurs enfants des méfaits du smartphone (exemple en Belgique : parentsconnectés.be, et l'article de la RTBF qui en fait la publicité). Dans ces conditions, l'étape suivante est facile à prévoir : ce sera la quasi virtualisation du smartphone, sous forme d'un implant.
Production numérique
Pour votre communication "de masse" (encore qualifiée de "globale"), préférez votre site web personnel c-à-d à nom de domaine propre. Cela vous donnera également plus de contrôle sur votre communication, et une estimation (beaucoup) moins biaisée de votre visibilité médiatique réelle ... (NB : les services gratuits n'ont pas pour objectif de maximiser votre visibilité mais de collecter vos données personnelles).
Notre programme d'auto-formation vous donne les bases pour développer votre propre site web (cf. supra #serveur).
Civilité numérique
La civilité numérique, encore appelée "netiquette", consiste en un ensemble de règles de vie en communauté, telles que le respect d'autrui, la politesse ou la courtoisie, dans le cadre de toute action impliquant l'usage de technologies de l'information. Bien sûr il n'y a pas de raison de distinguer civilités dans le monde "virtuel" et "réel". Mais l'absence de présence physique, l'éventuel anonymat, ou encore l'analphabétisme numérique (⇒ inconscience des effets de certains actes dans un monde hyperconnecté) stimulent malheureusement les incivilités dans le monde virtuel.
Étude
de cas
Nous allons traiter ici de la captation et diffusion non sollicitée de photos ou vidéos. Ainsi, par exemple, filmer des personnes lors d'une fête entre amis, sans leur avoir préalablement demandé leur accord, est abusif. Pour le comprendre, mettez-vous à la place des personnes qui ne sont pas le propriétaire de l'appareil de capture (souvent un smartphone). Elles peuvent légitimement se demander si le propriétaire sait exactement ce que fait avec les images l'application qui les traite. Les envoie-t-elle vers certains sites ? Et ce propriétaire n'a-t-il pas désactivé la mise à jour de son anti-virus (notamment par erreur) ? Ainsi n'a-t-il pas téléchargé sans le savoir un programme pirate qui détourne sons et images ? Ou plus trivialement, que va faire de ces images le propriétaire de l'appareil ? À qui va-t-il les montrer, et selon quels moyens ? Va-t-il les publier sur un "cloud" ? Dans ce cas de figure, comprend-il les implications de l'utilisation de ces services de stockage prétendument "gratuits" ? Cela alors que leurs fournisseurs abusent notoirement de l'analphabétisme informatique de la quasi totalité de la population, pour présenter leurs services de façon trompeuse ...
Lorsqu'un service Internet est "gratuit" c'est généralement parce que vous payez avec vos données (et celles de vos contacts). Lorsque l'on analyse en détails les conditions d'utilisation, on constate généralement que les mesures de "protection des données privées" consistent en réalité à accorder au fournisseur de service quasiment tous les droits d'utilisation de vos données. Voir à cet égard notre analyse du service /identification-authentification-internet#itsme (Belgique), qui révèle une collusion systémique entre milieux d'affaires et pouvoirs constitutionnels (exécutif, législatif, judiciaire).
Voici un cas typique, que l'on pourrait intituler "De fil en aiguille". Une personne prend des photos lors d'une activité de groupe, puis les télécharge sur la page d'un service "gratuit" de stockage d'images, puis en propage l'URL via des réseaux sociaux centralisés. Ceux-ci vont alors automatiquement enregistrer l'URL, télécharger le contenu du document correspondant (images, sons, textes), scanner ces éléments au moyen de logiciels de reconnaissance (IA), et enfin enregistrer l'ensemble de ces données (collectées et calculées) dans leur base de données relationnelle, de sorte que les réseaux relationnels personnels pourront être tracés et enregistrés (NB : tout cela automatiquement !). Ainsi, par recoupement de données personnelles collectées via différentes sources, la probabilité d'être identifiable et repérable, par des procédures automatiques, est extrêmement élevée.
Ainsi donc vous pensez ...
- n'avoir "rien à cacher" ... : jenairienacacher.fr
- que toutes des données collectées vous concernant sont "anonymisées" ... :
- logiciel : wikipedia.org/Footprinting.
- matériel : wikipedia.org/Empreinte_digitale_d'appareil
... et bien testez votre ordinateur/smartphone, pour vérifier si vous êtes aussi "anonyme" que vous le pensez ... !
Soulignons enfin qu'il peut exister des tas de raisons, tout à fait légitimes et honorables, pour lesquelles une personne peut souhaiter ne pas être photographiée dans tel lieu, à tel moment ou en présence de telles personnes. Aussi bienveillant soit le capteur d'images/sons, l'enfer (pour autrui...) peut être pavé de bonnes intentions. C'est notamment pour cela que personne ne devrait être tenu de justifier son droit à la vie privée.
Ne rentrent pas dans ces considérations la captation non sollicitée d'image et/ou de son d'une personne dans le cadre de son activité professionnelle. Je pense notamment aux policiers et aux journalistes : tout citoyen devrait avoir le droit de filmer et/ou enregistrer ceux-ci dans le cadre de leur activité professionnelle.
